[Sony]独自のグラフィック技術に関する特許申請
Push Square の記事を翻訳いたしました(個人名は原文のままです)。
訳文の一番下にあるボタンからソースのページに移動できます。
ソニーは独自のグラフィック技術を探求しているかもしれません
DLSS に似て非なる
ネイティブ過ぎぬ画像
Sammy Barker Wed 2020.7.29 1:00
この記事内の画像はすべてクリックで拡大可

ここ数年私たちは何を学びましたか?
簡単です。ネイティブ 4K はマシンパワーの浪費です。そのことは、ソニー独自の(PS4)本体性能の検査官役たる『Horizon Zero Dawn』のようなゲームにおいてすでにその点を証明しています。
一方で、NVidia 独自の DLSS(ディープラーニングスーパーサンプリング)が実用化され、ゲームに実装されています。
ご存知ない方のために説明すると、とはいえ私たちはこの分野の専門家からはほど遠いわけですが、DLSS は人工知能を使用して、低解像度の画像を高解像度の画像の品質で再現します。つまり、代替的ネイティブの解像度で効果的にレンダリングし、それに伴うハードウェアパフォーマンスのメリットをすべて享受しながら、最終的に非常に鮮明な画像を表示することができます。
訳者注
動画の右半分が DLSS によるものです。
Death Stranding with NVIDIA DLSS 2.0(2020/07/14)
これはゲーム変革者たり得る技術ですが、PlayStation は独自の解決策を模索しているようです。
プラットフォーム保有者が申請した特許は「情報処理装置」であり、具体的には「物体の様子を表す再現画像を生成するための事前学習データ(以下略)」を活用できる技術を提案しています。
あいまいですが、門外漢からすると DLSS に似ています。
では、このような技術の利点とは?
まあ、ネイティブ 4K は計算コストがかかります。これらのピクセルをすべてレンダリングするには、多くの処理能力が必要です。DLSS は、上記の馬力を、物理、エフェクト、AI、照明、フレームレートなど、他の処理に割り当てることができることを意味します。しかも、全体的な画像品質に影響を及ぼす劣化はありません。
公平を期すために、ソニーはハードの限界に挑むタイトルでもって印象的な仕事をしたので、今後の展開と可能性を想像して興奮しています。
補足 dsll
記事にあるように、低解像度の画像をもとに高解像度画像を生成する技術です。
一応直訳しておきますが、「深層学習による超越的(画像データの)標本化」。
2020年4月の時点で、このテクノロジィは GeForce RTX 20 シリーズの GPU でのみ利用可能です。
これを採用した代表的なゲームを挙げると以下の通りです。タイトル後ろのカッコ内は、バージョンを示す数字ですが、一般的な「ver 数字」 ではなく、「DLSS 数字」という表記です。
- Battlefield V(1.0)
- Metro Exodus(1.0)
- Control(2.0)
- Wolfenstein: Youngblood(2.0)
なお、初期の DLSS 2.0 の場合、機械学習を使用していません。
また最新の、後期 DLSS 2.0 では、アンチエイリアス処理がやや弱いという副作用があります(現時点)。
以下は『Metro Exodus』において DLSS を無効にした画像(左)と有効にした画像(右)です。画像のカメラアングルはわずかに異なります。


補足 以下略
で済ませたくない方のために。
まずは、特許に冒頭に記されている技術の要約を。
再生対象を撮像して得られた複数の参照画像を取得し、複数の参照画像をそれぞれ拡大または縮小して得られた複数の変換画像を取得し、複数の機械学習を実行する情報処理装置学習データとして、複数の変換画像を含み、オブジェクトの外観を表す再現画像を生成するために使用される事前学習データを生成する。
この要約は厳密なのですが難解なので、以下に簡単なご説明を。
まず重要なのが、この技術は 3DCG に限定する画像処理技術ではありません。特許説明の冒頭に、「機械学習によって画像を自動生成する技術研究の試みの一つ」とあります。
ただ、3DCG にも適用できるようなので、まずは現行の最も基本的な処理を説明します。記事本文もそのように論を展開してます。
ご存知かとは思いますが、ゲームをはじめ 3DCG という技術は、3D データ(形状、色等の定義)をもとに GPU が画像(最終的にディスプレイに表示されるもの)を演算(生成)します。それが、あなたが具体的に目にする画像です。
さて、ソニーによる技術の最終目的は「(撮像していない)オブジェクトの外観を表す再現画像を生成」することです。再現画像とは、上述の「自動生成された画像」をさします。そのために、AI による学習が必要と定義しています。
学習の過程として、対象物を撮影することから始まります(以下の左の画像)。さらにその拡大・縮小画像からも AI が学ぶようです(以下の右の画像)。
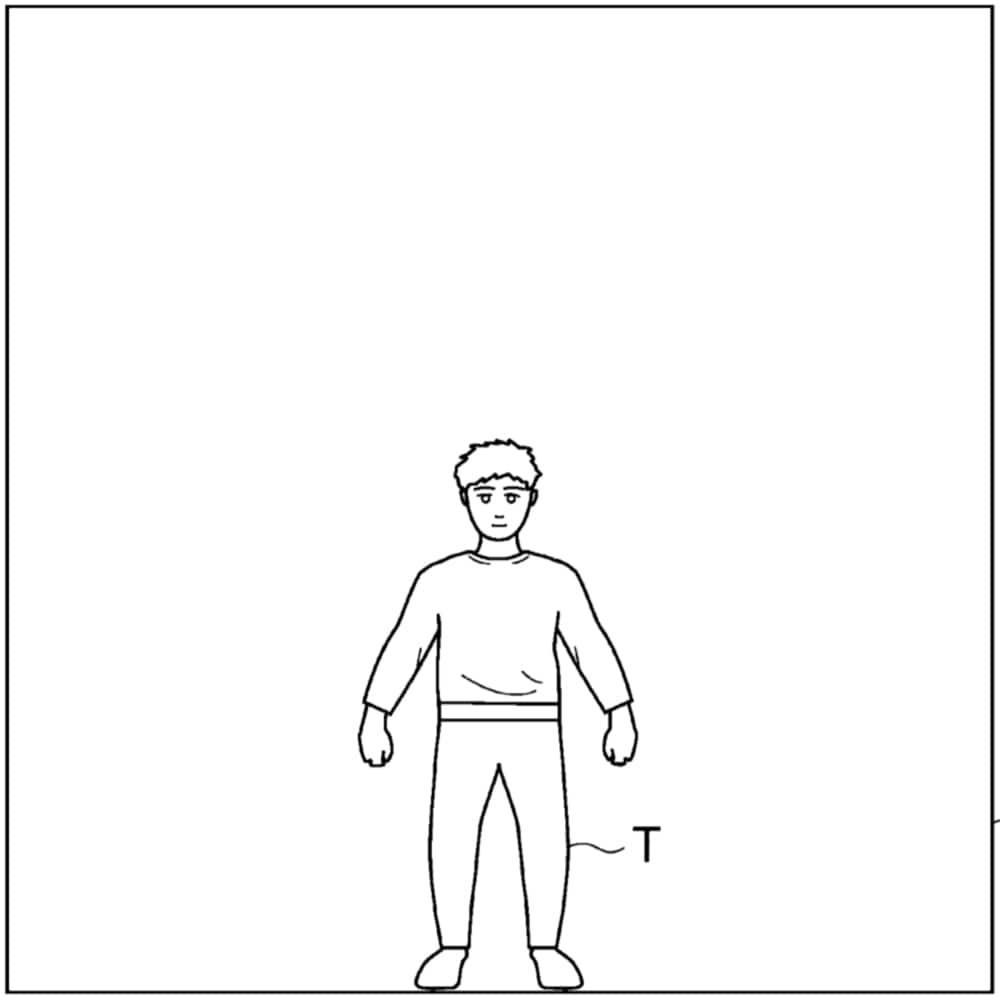
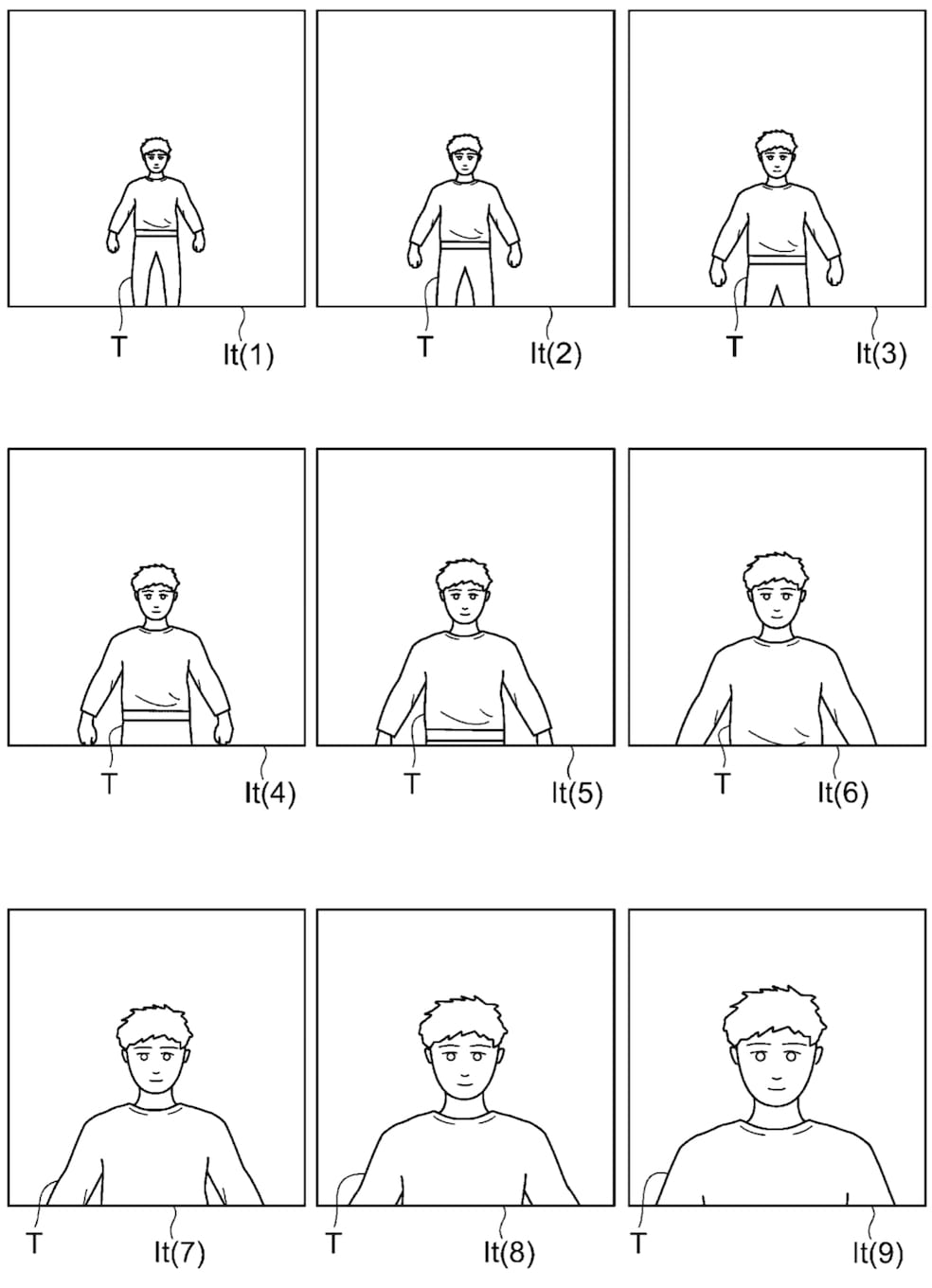
特許で取り上げられている理想とする画像処理は、ものすごく単純に要約すると、学習することにより、対象物の 3D データに基づいた「正直な処理(演算)」を行う必要がなくなるようです。 にも関わらず、ほぼ、従来と同じ画像を生成できるということです。
ゲームに適用される場合、上記の「再現画像」というのはディスプレイに表示されるピクセル画像(2D)という理解で問題ないかと思います。
DLSS との違いは、学習すれば逐一「低解像度の画像を生成するための 3D 演算」すら実行しなくてよいということを示唆しています。AI が正しく学習すれば。
実現(実装)すれば、GPU への負荷は相当軽減されるものと考えられます。
ちなみに、AI が学習のために必要とするデータを「教師データ」と言います。
なお、基準となる(例として人物の)画像をもとに、その「姿勢を特的」することも可能であることが以下の図により示されています(前出の画像も再びご覧になると良いかと)。
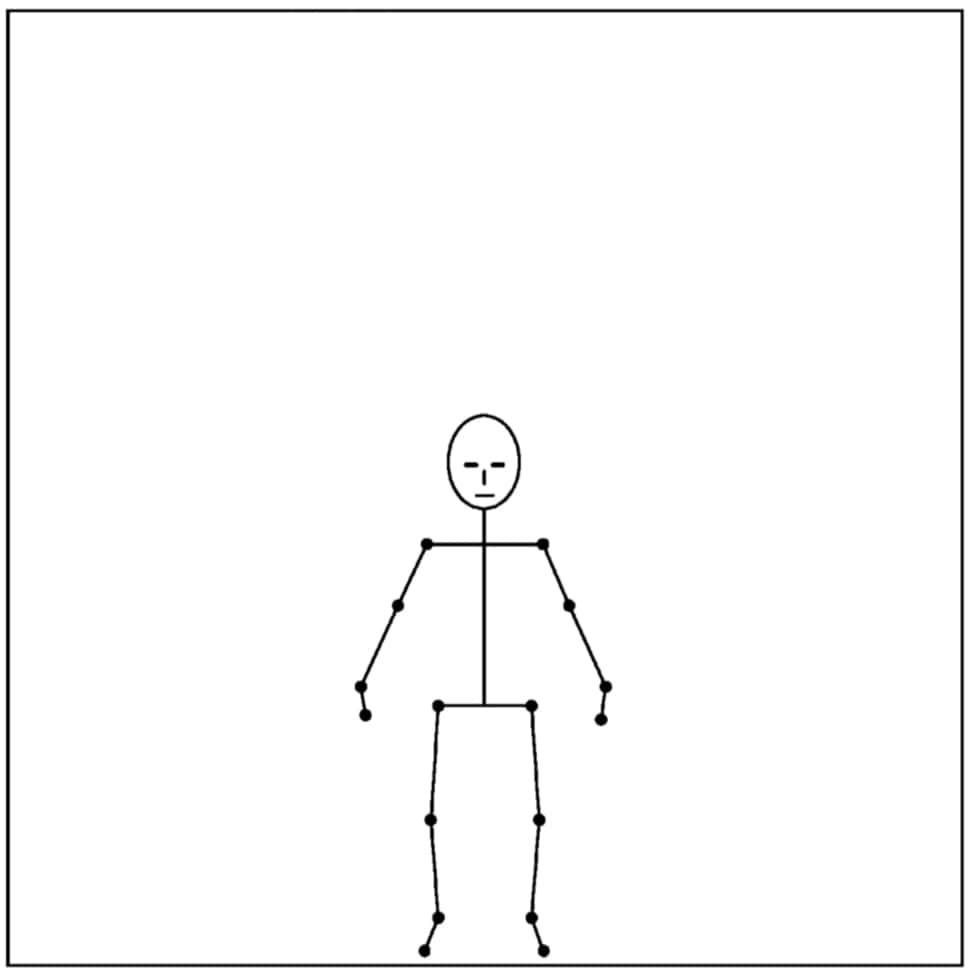
申請された特許に関しては、Freepatents online から PDF を無料でダウンロードできます。
そもそも画像を認識するとはどういうことか、根本的なところを考えされられます。
脳にしろ AI にしろ。あなたが見るものは、「本物か偽物か」
もはやそういう概念ではないかもしれませんが。
あるいは、「(牛は)小さいか遠くにあるwww」